
HandMap: Robust hand pose estimation via intermediate dense guidance map supervision
In ECCV 2018. Other authors on the paper: Yongliang (Mac) Yang, Daniel (Dan) Finnegan, Eamonn O’Neill.
Problem statement and motivation
The goal is to accurately estimate hand pose, i.e. 3D location for each joint, given single depth image.
Why is the topic important?

Robust hand pose estimation is essential for emerging applications in human-computer interaction, such as virtual and mixed reality, computer games, and freehand user interfaces. The hand is also the most flexible and expressive part of human body, so the study of hand poses provides a great source of input to human behavior recognition task, which further benefits studies in computer vision in general.
Why is the problem difficult?
The difficulties come from several sources:
- Human skin is relatively uniform in color and surface property, which can only provide weak feature descriptors.
- Strong ambiguity due to self-similarity between fingers.
- The area of hands in a full-body size image is often very small, which means low signal-noise ratio.
- Severe self-occlusion, especially in interactive applications.
Justify the use of depth image
Traditional computer vision algorithms usually focus on color channels, which can hardly provide robust output given the challenges listed above. But nowadays depth cameras are becoming much easier accessible (e.g. my $800 laptop in 2016 has a built-in depth camera), which provides extra geometric information in the depth dimension. Many recent works found that this added accuracy can cope with spatial ambiguity problem well.
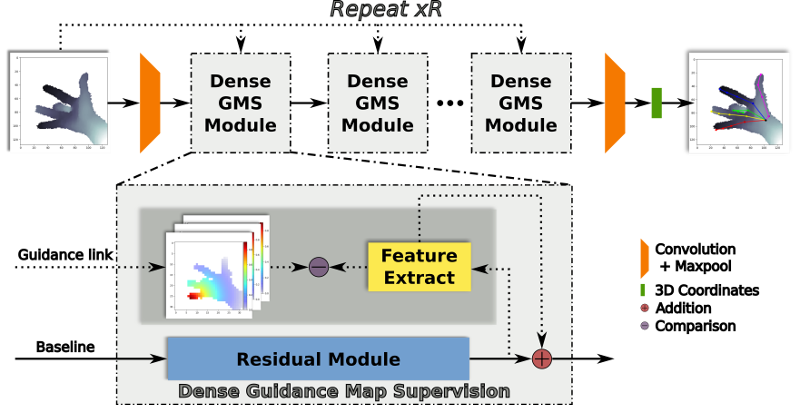
Robustness - intermediate supervision
Some recent works have observed that adding supervision in the intermediate stages of the pipeline can produce better results - higher accuracy and more stable convergence. In our work, We following the intermediate supervision approach: guidance maps are adopted in our pipeline to produce hidden space supervision.
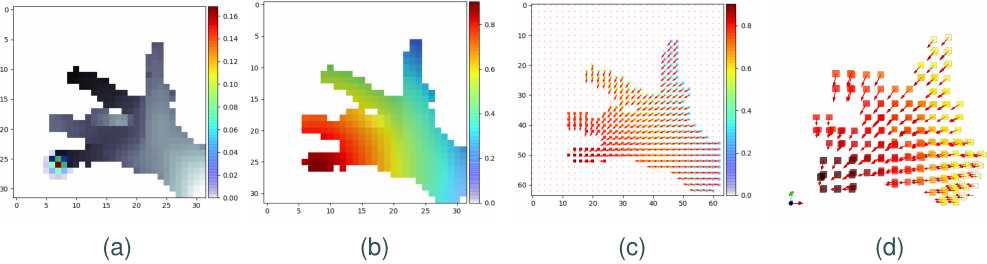
Sparse vs dense guidance maps
Most of the previous works use sparse guidance maps, e.g. heatmaps (Fig~1 a) that show the probability of each target joint. In our approach, we mainly discuss “dense guidance maps” - the confidence score extends to the entire input domain (Fig~1 b-d).
The failure of sparse supervision approach
Think about the characteristics of probability maps before moving on - we can easily find there is a dilemma of choosing the variance:
- In order to produce high accuracy results, the variance needs to be set as a small value, which means compact local support.
- But in case of detection task with noisy input - especially for hand joints detection - too small local support can not well differentiate ambiguous similar-looking locations, which leads to many false positives.
So we need a different way of providing hidden space guidance - this is the main starting point of our work.
Euclidean distance function
In our study, we are mostly interested in geometrically meaningful dense guidance maps. The most straightforward idea is just using Euclidean distance function, and maybe adding more attributes for stronger guidance (Fig~1 b-d). The problem is obvious: spatially close points do not imply correspondence, e.g. the tips of pinky and ring finger are wrongly judged as close in Fig~1 b.
Geodesics
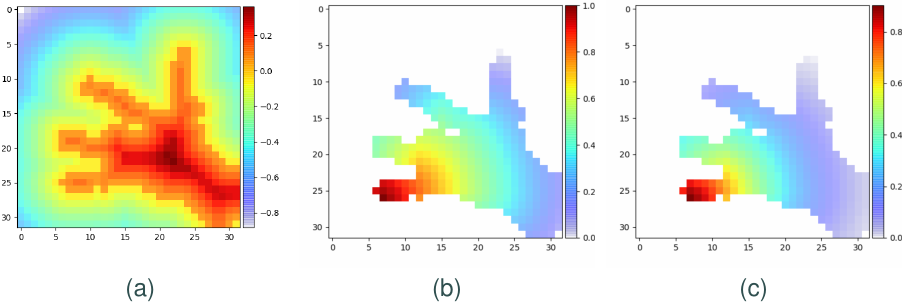
So we propose to use geodesic distance functions, for a better measure on the surface of the hand. As shown in Fig~2 b-c, our algorithm can correctly tell the distance from the tip of the pinky finger to other points on the hand.
Approximation
The problem of using geodesics is that computation cost is high, especially for calculating the distance functions for each joint of a sample hand in a very large training dataset. Notice the assumption of $R^3$ is problematic - our input depth image is only “2.5D” by definition, as we can only capture partial surface that is visible from one viewpoint. So we adopted an approximation strategy: we first calculate the 2D (signed) Euclidean Distance Transformation (EDT), then we can propagate distances from each joint location using Fast Marching Method (FMM).
Framework
The main idea is to leverage the feature extraction effectiveness of the residual module through guidance map supervision, which further enhances the entire system’s learning strength by combining the residual link.
Pipeline
The pipeline of our algorithm starts from a single depth image. Our baseline method (shown in solid line) stacks R repetitions of a residual module on lower dimensional feature space, then directly regresses 3D coordinates of each joint as in a conventional CNN-based framework. In comparison, our proposed method (shown in dashed line) densely samples geometrically meaningful constraints from the input image, which provides coherent guidance to the feature representation of residual module.
“Stand on the shoulder of giants”
Our algorithm alone might not fully convince you. But please note that the core Dense GMS Module in our algorithm is “hot-pluggable”: we can easily plug it into other state-of-the-art (SOTA) methods, and achieve better performance due to added robustness. Please check the paper for details about evaluation metrics and performance enhancements.
In short: the best of our standalone algorithms is roughly comparable to the SOTA, but we achieved much better performance after combined our algorithms with the SOTA.
“Forthcoming Research” already came
In the poster that I prepared for the ECCV2018 conference, you can see that:
Future work will explore temporal hand tracking using our framework …
Well, actually this has already been realized:
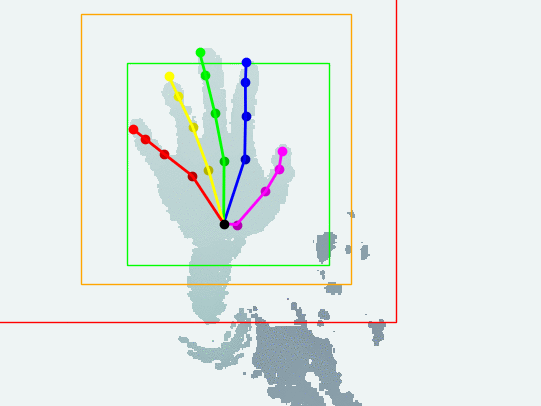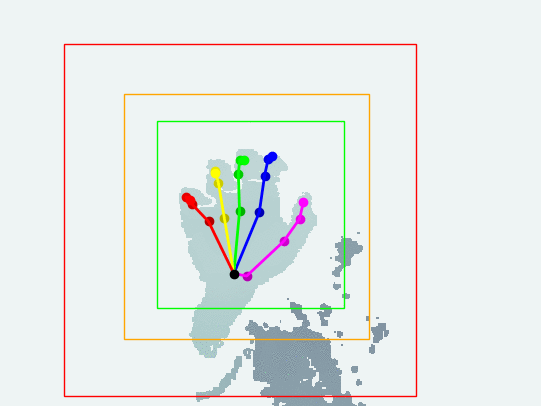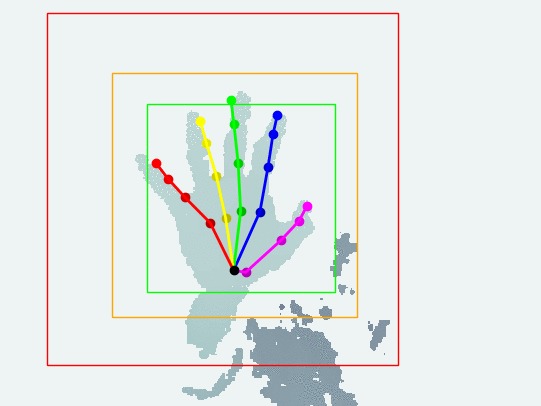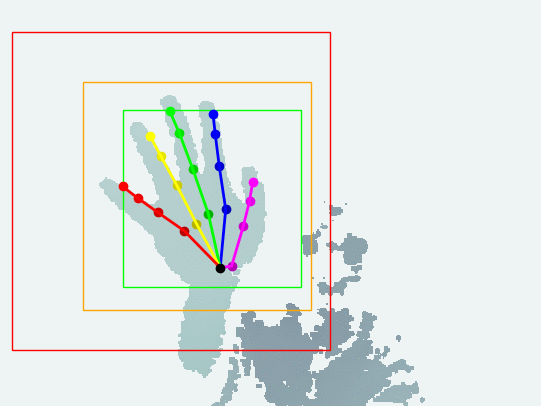
Please visit the hand tracking project if you are interested.
Appendix: Abstract
This work presents a novel hand pose estimation framework via intermediate dense guidance map supervision. By leveraging the advantage of predicting heat maps of hand joints in detection-based methods, we propose to use dense feature maps through intermediate supervision in a regression-based framework that is not limited to the resolution of the heat map. Our dense feature maps are delicately designed to encode the hand geometry and the spatial relation between local joint and global hand. The proposed framework significantly improves the state-of-the-art in both 2D and 3D on the recent benchmark datasets.
Appendix: Related work
Please take a look at xinghaochen/awesome-hand-pose-estimation: it’s simply the best survey repo on the topic of Hand Pose Estimation.